基于RNN的LSTM长短期记忆神经网络
RNN 神经网络
RNN(Recurrent Neural Network, 循环神经网络) 的目的是用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,而每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的 节点 不再无连接而是 有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
其展开图如下:
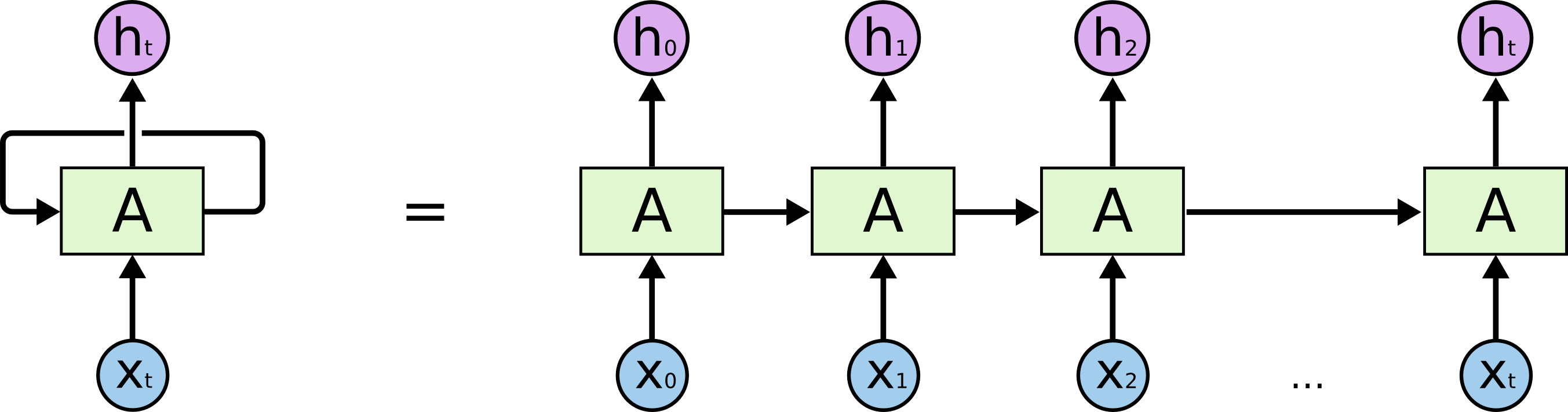
其中,h1 状态包含着 x0 和 x1 的信息,h1 状态包含着 x0, x1, x2 的信息,以此类推,ht 里包含着所有的输入信息, 可以把 ht 看作为从 x0, x1 ··· xt 整个输入信息里提取到的特征向量。
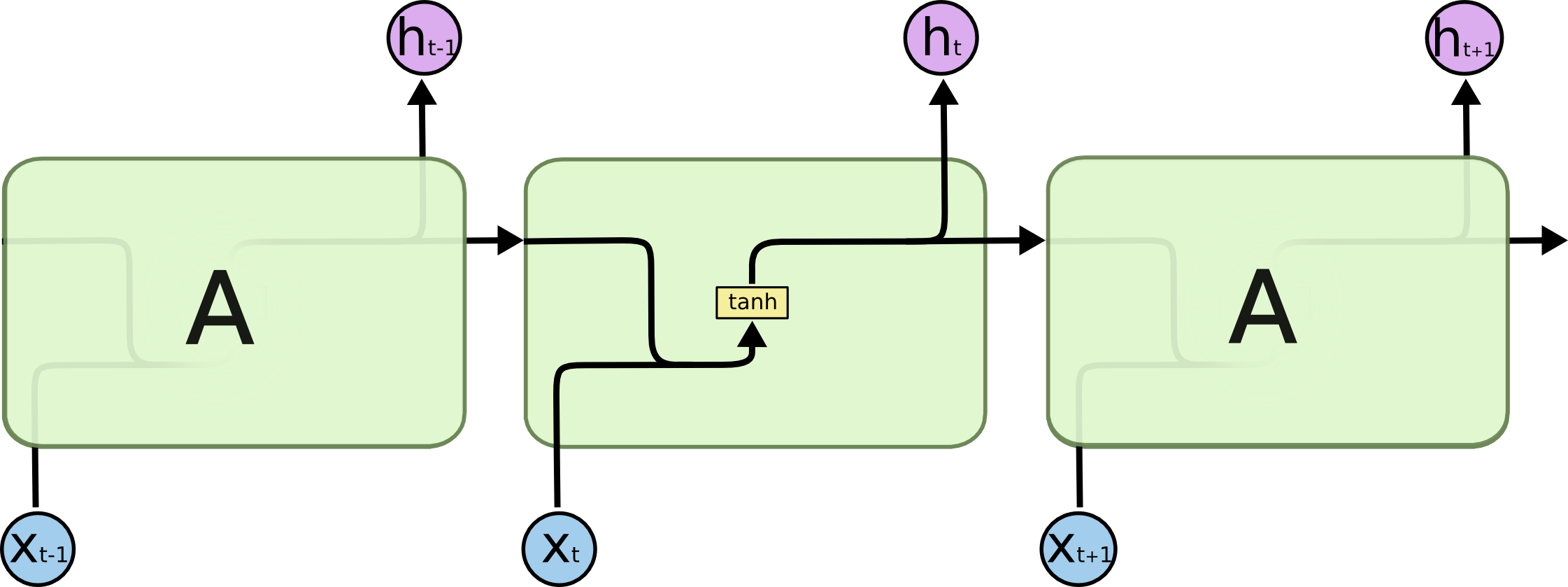
更新每个状态 h 的时候需要用到参数矩阵 A, 需要注意的是整个RNN只有一个参数矩阵 A,一开始 A 随机初始化,然后利用训练数据来学习 A. 但在此过程中,如果矩阵向量 A 的特征值大于 1,或者小于 1,并且循环次数很大的情况下,可能会变成接近于 0,或者变成很大的值。从而导致 梯度消失 和 梯度爆炸。
LSTM 神经网络
LSTM(Long Short Term Memory, 长短时记忆网络) 模型,是在RNN模型的基础上作出改进,解决了RNN短期记忆的问题 (梯度消失和梯度爆炸)。
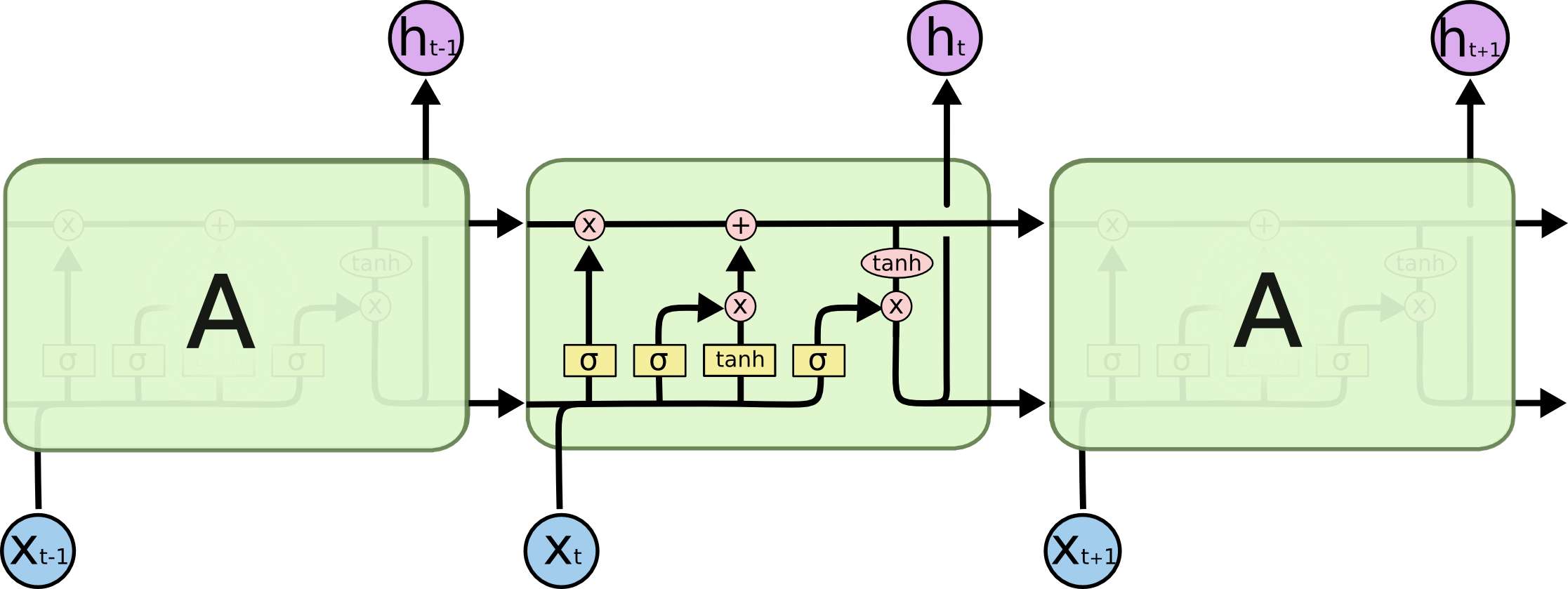
LSTM在RNN的基础结构上增加了遗忘门、输入门、输出门三个单元,它有四种参数矩阵。
遗忘门
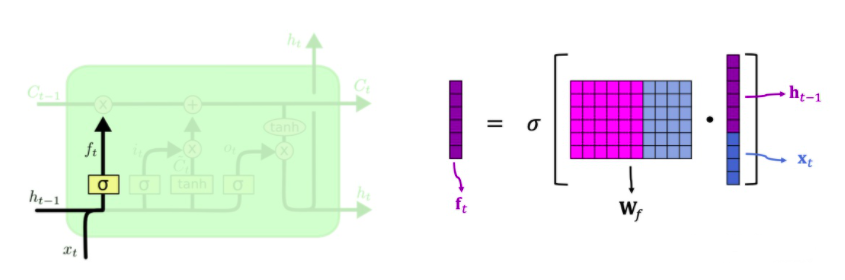
求遗忘门ft 的方法 : 先把上一时刻的 h_t-1 与当前输入 xt 连接,然后与遗忘权重矩阵 Wf 相乘,结果做 sigmoid。
ft 的每一个值都在 0-1 之间,比如为0时,就是要忘记,为1时,就是全部通过。所以遗忘门 f 可以有选择地让传输带 C 的值通过。即C * f = output
输入门
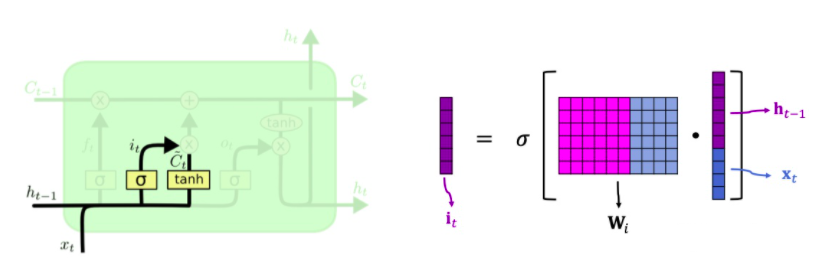
求输入门ft 的方法 :和遗忘门类似,把上一时刻的 h_t-1 与当前输入 xt 连接,然后与输入权重矩阵 Wi 相乘,再通过 sigmoid 函数得到 i_t.
new value

求new value_Ct 的方法 :与遗忘门和输入门类似,但是使用的激励函数不一样,一般使用tanh函数,所以向量的每一个值都在 -1~1 之间。计算 _Ct 也需要一个权重矩阵 Wc.
更新传输带Ct
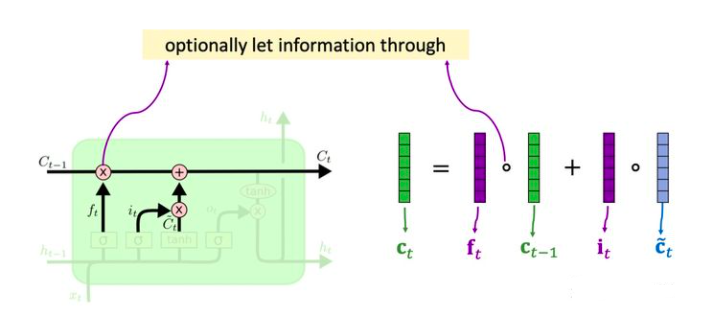
我们已经求出遗忘门ft,输入门ft,还有new value_Ct,我们还知道传输带旧的值 C_t-1,现在可以更新传输带 Ct 了。
更新传输带 Ct的方法(如上图):
遗忘门ft 选择性地遗忘旧传输带 Ct-1 中的一些元素。ft * Ct-1(1)现在要往传输带上添加一些新的信息。也就是
输入门ft 向量与new value_Ct 向量相乘。i_t * _Ct(2)新的传输带 Ct 值就是上一时刻的值 Ct-1 通过遗忘门删除一些值,通过
输入门添加一些新值得到的,也就是 (1) + (2)。Ct = ft * Ct-1 + i_t * _Ct
输出门
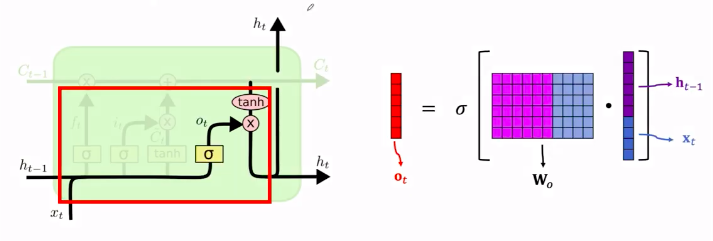
与遗忘门和输入门算法一样。输出门也有自己的参数矩阵 Wo.
更新状态向量 h_t
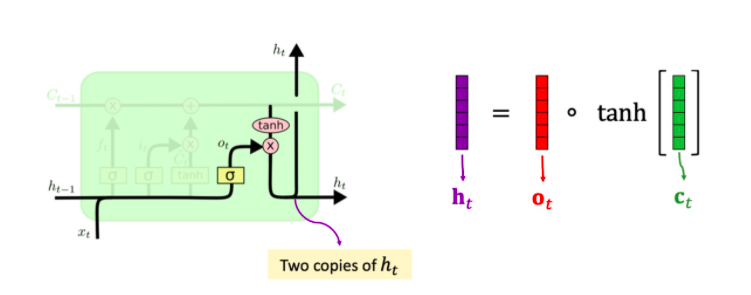
求出 h_t的方法 :
- 对
传输带 Ct每一个元素求tanh双曲正切,把元素都压到 -1~1 区间。 ht = Ot * tanh(Ct)
这样,可以认为所有输入的 x 信息都积累在状态向量 ht 里面。