数据切分策略
Contents
背景
随着业务的快速发展,海量数据与其高效使用已成为企业关注的重点问题。当数据量达到一定限制之后,企业面临着如何缓解数据库的性能问题,初步的方案可以为优化数据库索引,但它不可能成为持久的解决方案。为了持续保证数据库性能健壮,务必从数据层面对问题寻找方案,即需以有效的策略对数据进行切分。
数据切分
数据库分片,即Sharding的基本思想是将海量数据切分到不同的数据库中,从而缓解单一数据库的性能压力。数据库分片的意义在于把数据分到不同的物理机的数据库中,增加主机的数量,这样可以减轻单一物理机的CPU、内存、网络IO方面的压力,为此实现提升性能。
数据切分分为两种:垂直切分 和 水平切分。
垂直切分
垂直切分分为 垂直分库 与 垂直分表。垂直分库是根据业务需求,将关联度较低的数据表分散存储到不同的数据库中;垂直分表是当某一表字段较多时,可以通过创建新的扩展表的形式对“大表”进行拆分,将不常用的字段或者长度较长的字段拆分到另一张扩展表中,以主键进行关联。

简单来讲就是以不同的表或者表字段为单位,把数据存储到不同的数据库中。
优点
- 业务明确,降低各业务间的耦合度;
- 在高并发的场景中,一定程度上能缓解网络IO以及数据库性能问题。
缺点
- 无法进行join操作,只能通过接口聚合方式解决,提升了开发的复杂度;
- 对于单表数据量行数过大的情况,效果不大。
水平切分
对于单表数据量行数过大的情况,存在单表读写、存储性能瓶颈,单靠垂直切分不够,需要考虑水平切分。水平切分是在同一个表里,根据特定规则,将数据按行分散存储到不同的数据库中,这样每个数据库只存储部分数据,达到分布式的效果。
优点
- 对于单表数据行过大的情况,有效避免性能瓶颈;
- 不需要额外拆分业务。
缺点
- 跨库的join操作较缓慢;
- 后期修改表结构或者维护困难;
水平切分时,一般通过特定规则,将一张表拆分存储在不同的数据库的数据表中。以下为较为常见的切分方法:
1. 根据数值范围切分
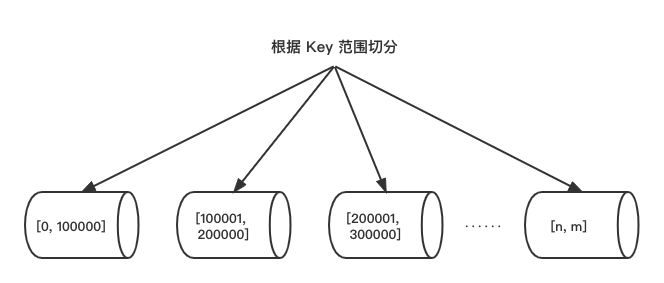
根据业务需求,可通过数据表的ID或者时间范围来进行切分。如图所示,将 key 的取值范围为[1,100000]的数据分到第一个库中,取值范围为[100001,200000]的数据分到第二个库中,取值范围为[200001,300000]的数据分到第三个库中。若以根据时间范围切分举例,可以把把1,2,3月份数据放到第一个数据库中,4,5,6月份数据放到第二个数据库中,以此类推。
优点
- 可以有效控制单表数据量过大的情况;
- 便于后期扩容,只需要添加节点即可;
- 当查询连续数据时,可快速在定位分片里进行查询,不用跨分片查询;
缺点
连续分片可能存在热点数据,即有些分数据频繁被读写,而有些很少被调用。
2. 根据数值取模切分
一般采用hash取模的方式,对数据进行切分。例如,将对 key 模 3 取余数,余数为0的数据分到第一个数据库中,余数为1的数据分到第二个数据库中,余数为2的数据分到第三个数据库中。
优点
数据分片相比较均匀,出现热点数据的可能性较小;
缺点
- 如果查询条件中不包括此 key,则较难确定数据具体分布在哪个数据库,所以需要向所有数据库进行查询,并在内存中合并数据,取交集返回。
分库分表带来的问题及解决方案
1. 跨库join查询问题
在应用中通过join来关联查询多个表是较为普遍的场景,而将数据切分到不同的数据库之后,join操作就变得不简单了,跨库的join则带来性能和安全方面的问题,考虑到架构规范也是不提倡的。
解决方案
全局表
维护一些表,用来存放所有模块可能共同依赖的字段,为了避免垮库join查询,所有节点都需维护这些表。在这里需要注意的是,这些字段应当为修改频率较低的字段,比如id、日期这种属性,不然维护起来难度较大,可能会带来数据不一致的新问题。字段冗余
这是一种以空间换时间的思想。例如,设计订单表的时候,除了定义userId之外,再定义usnerName冗余一份,这样可以不同通过join来关联查询。
2. ID主键重复问题
主键为保证某一条数据唯一性的唯一标识。在分库的情况下,如果通过自增ID的方式创建主键的话,会导致多条数据主键重复的问题,这样显然不可行。为了保证主键的唯一性,必须设计一个满足要求的特殊形式ID。
解决方案
1. UUID
UUID = 4个连字号(-) + 32个字节长的字符串,总共36个字节长。比如:
550e8400-e29b-41d4-a716-446655440000
优点:
能够保证 独立性,程序可以在不同的 数据库间迁移,效果不受影响。
缺点:
- 不易于存储 / 性能问题:UUID太长,128位、36长度字符,不利于Mysql索引(在InnoDB引擎下,
UUID的无序性可能会引起数据位置频繁变动,严重影响性能),很多场景不适用。 - 采用
无意义字符串,数据量增大时造成访问过慢,且不宜排序。 - 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
2. 雪花算法

算法描述:
- 最高位是符号位,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据
时间进行排序。 - 10位的
机器标识,10位的长度最多支持部署1024个节点。 - 12位的计数序列号,序列号即一系列的
自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
此外,还存在事务一致性、跨节点分页、排序、函数等问题。
总结
那我们该什么情况下需要考虑数据的切分?其实,能不切法尽量避免切分。数据切分所带来的问题较难控制,有些解决方案也不够成熟。只有在数据量过大,正常运维影响业务访问,或者随着业务发展,需要对某些字段垂直切分的情况下,可以考虑数据切分。此外,数据切分可以在一定程度下提升数据的安全性和可用性,当某个节点出现问题的时候,不会影响到所有的业务处理,因为数据是分布存储到多个节点的,存储在其他数据库的数据将不会受到影响。